










連載
西川善司の3DGE:AMDのGPU「RDNA 4」完全解説。既存のゲームをそのまま高速化する新技術の数々が明らかに
 |
 |
 |
ADVANCING AI 2025の会期中,AMDは,RDNA 4のアーキテクチャの解説を行った。本稿では,その内容をベースに,AMDの新世代GPUアーキテクチャの注目すべきポイントについて解説したい。
●目次
- RDNA 4アーキテクチャベースのRadeon GPU
- Navi 31よりも減ったShader Engine。最上位RDNA 4はまだこれから
- RDNA 4のCompute Unitにおける特徴
- 推論アクセラレータのFP16演算性能はRDNA 3比で2倍に
- Ray Acceleratorの改善(1)〜BVH8への対応と2倍に向上したレイ探索効率
- Ray Acceleratorの改善(2)〜BVHにOBB導入
- RDNA 4のメモリ,キャッシュ階層システム
- 順不同メモリアクセスシステム「Out of order Memory」
- 動的割り当てに対応したVGPR
- RDNA 4はゲーム側の改変なしで効く新機能が多い
RDNA 4アーキテクチャベースのRadeon GPU
RDNA 4アーキテクチャ採用のGPUは,本稿執筆時点で「Navi 48」と「Navi 44」の2種類がある。上位モデルがNavi 48で,下位モデルがNavi 44だが,この命名規則は,従来とは異なるものだ。
これまでのAMDやNVIDIAは,GPUチップの命名規則において,上位モデルの数字を小さくしていた。今回はこれが逆転しているのだ。今回,製品名としてのRadeon RX 9000シリーズの命名規則が変更されたわけだが,何か関係があるのだろうか。
RDNA 4ベースのGPU製品のスペックをまとめたのが,以下の表になる。
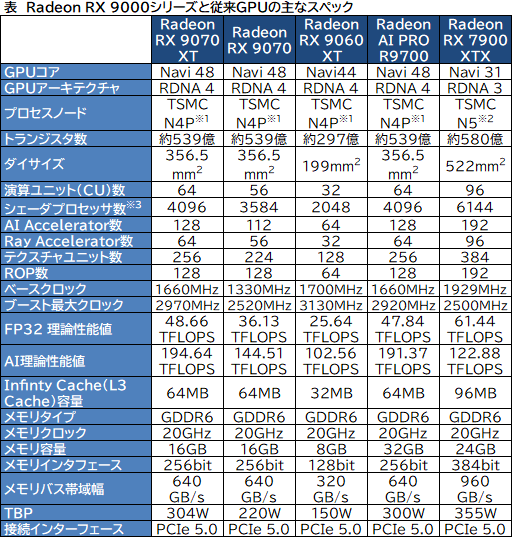 |
チップレットアーキテクチャを採用した「Radeon RX 7900」シリーズの「Navi 31」や,「Radeon RX 7800/7700」シリーズの「Navi 32」とは異なり,Navi 48/44は,単一のモノリシックダイとなっている。製造プロセスノードは,TSMCの「N4P」だ。
TSMCの「N4」は,5nm相当といわれていた「N5」の改良版に相当する。そのN5から,トランジスタ性能を11%,密度を6%向上させたものがN4Pだ。
ダイサイズは,Navi 48が356.5mm2で,Navi 44が199mm2。トランジスタ数は,Navi 48が約539億個で,Navi 44が約297億個だ。チップの規模的には,Navi 48は,TSMCの4Nプロセスを採用した「GeForce RTX 5080」の「GB203」(456億,378mm2)や,Navi 44は「GeForce RTX 5070」の「GB204」(311億,263mm2)あたりに近い。
ちなみに4Nプロセスは,NVIDIA専用プロセスだが,N4Pの方があとで登場したこともあり,性能は4Nよりも高いと言われる。実際,動作クロックは,N5ベースのNavi 31や,4NベースのGB203やGB204よりも高い。
接続インタフェースは,PCI Express(以下,PCIe) 5.0に対応した。AMD GPUとしては,RDNA 4が初めてのPCIe 5.0対応となる。
Navi 31よりも減ったShader Engine。最上位RDNA 4はまだこれから
Navi 44は,Navi 48の縮小版なので,Navi 48に注目して,その構造を詳しく見ていこう。
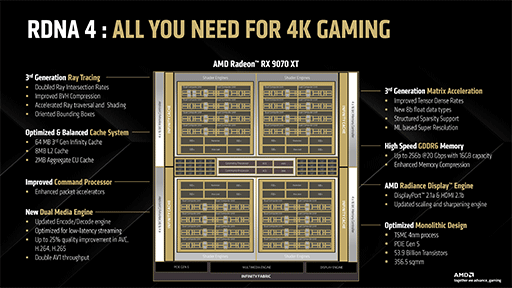
Navi 48の全体ブロック図は下記のようになる。
 |
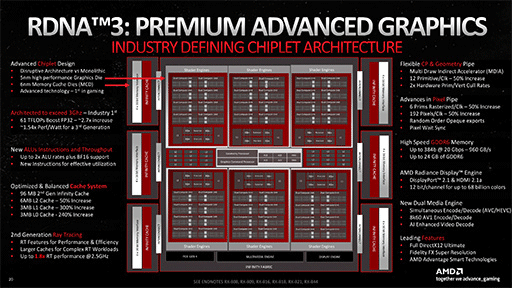
参考までに,Navi 31とNavi 21(Radeon RX 6900 XTおよびRadeon RX 6800シリーズ)の全体ブロック図も掲載しておこう。
 |
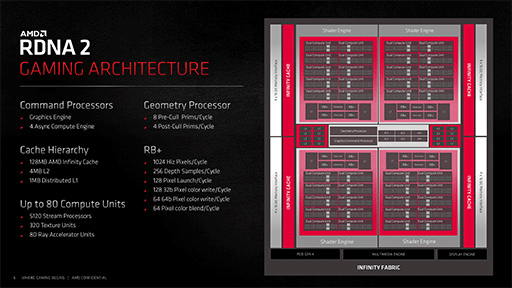 |
これらのブロック図を見て気づくのは,Navi 48は,Navi 31よりもNavi 21に近い構成ということだ。
Navi 48は,ミニGPU的なクラスタである「Shader Engine」(以下,SE)や,Infinity Cache(≒L3キャッシュ)とメモリコントローラのブロックを,4つまとめて1つのGPUを構成している。これは,Navi 21の構成と同じだ。
SEは,NVIDIAのGPUでいうところの「Graphics Processor Cluster」(以下,GPC)と同じ扱いで,この数が事実上,GPUの規模を表す。Navi 31では,SE数が6基なので,Navi 48では4基に減少したことになる。
シェーダプロセッサ総数も,Navi 31の6144基に対して,Navi 48では4096基と少ない。
もしNavi 48が,RDNA 4世代の最上位GPUだとすれば,AMDはRDNA 4で,GPU規模を,先代比で一回り小さくしたことになる。これまでGPU業界では,大きなアーキテクチャ改変で規模を維持はしても,小さくすることはほとんどなかった。AMD側のGPU戦略に,大きな変化が起きているのだろうか?
ちなみに,NVIDIAの最新Blackwell世代の最上位GPU「GB202」は,先代Ada Lovelace世代の最上位GPU「AD102」と比較すると,GPCの数はどちらも11だが,GPC 1基あたりのシェーダプロセッサ数は,約1.3倍に微増している。つまり,全体的なGPU規模は,約30%ほど増えていた。
今回のイベントにおいて,AMDは,AI向けGPUの次世代機となる「CDNA 5」や「CDNA 6」については予告していたが,RDNA 4世代GPUの拡充に関しては言及しなかった。「SE数が6基以上に増えたRDNA 4世代GPUが,『RX 9080』型番でリリースされるのではないか」という希望を込めた噂もあるが,はたしてどうなるだろうか。
RDNA 4のCompute Unitにおける特徴
AMDのRDNA系アーキテクチャでは,GPUコアに相当する「Compute Unit」(以下,CU)2基を1ペアとする「Dual Compute Unit」(CUペア)とする考え方がある。最近では,これを「Work Group Processor」(WGP)と呼ぶことも多い。
そしてNavi 48では,4基あるShader Engineが,8個のWGPを備えているので,それはCU 16基とカウントできる。つまり,Navi 48全体のCU数は,以下のとおりだ。
- 2 CU×8 WGP×4 SE=64 CU
Navi 44はSE 2基構成なので,CU数はこうなる。
- 2 CU×8 WGP×2 SE=32 CU
では,RDNA 4のCUは,どのような進化を遂げたのかを深く見ていこう。
大前提として,AMDがRDNA 3で行った大改革のようなことは,RDNA 4では行っていない。
RDNA 3での大改革とは,WGPあたりのSIMD32演算器を8基に,つまりCU 1基あたり,SIMD演算器が4基に倍増したことだ。
関連記事



西川善司の3DGE:Radeon RX 7900 XTX/XTは何が変わったのか。大幅な性能向上を遂げたNavi 31世代の秘密を探る
AMDの新世代GPU「Radeon RX 7900 XTX/XT」は,内部アーキテクチャを刷新した「RDNA 3」世代へと進化した。GPU初のチップレットアーキテクチャ採用や,内部構造の変更点,AI処理ユニットの新設やレイトレーシングユニットの強化点など,その詳細を明らかにしてみよう。
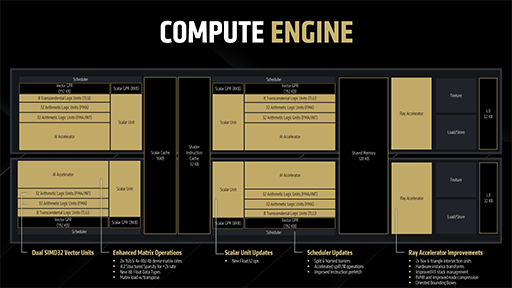 |
AMDはRDNA 4のCUに行った大きな変更点は,スカラユニットに32bit浮動小数点演算(FP32)のネイティブ命令を追加したことだ。
RDNA 3でも,スカラユニットで単精度のFP32演算は行えた。しかし,RDNA 3以前では,ベクトル演算ユニット(SIMD演算器)にFP32演算を外注していた。
具体的には,「SGPR」(スカラレジスタ)から「VGPR」(ベクタレジスタ)にコピーして,ベクトル演算ユニット(SIMD演算器)に演算処理を行わせたうえで,演算結果をVGPRからSGPRに返していたのだ。
それがRDNA 4では,ネイティブで実行できるようになった。冗長な部分が一切なくなるのだから,効果としては大きい。
RDNA 3まで,ネイティブ命令に対応していなかったのは,スカラユニットでの浮動小数点演算は,使用頻度が低かったからだという。しかし近年では,AI関連処理でFP32データに対する前処理や後処理で,浮動小数点演算の利用頻度が高まったため,RDNA 4では対応をしたようだ。
そういえば,2025年末にリリース予定のAI高画質化技術「FSR Redstone」に含まれるニューラルレンダリング技術は,推論アクセラレータである「AI Accelerator」を使わず,Compute Shaderコードで実行されるとされるという。
そうした処理系の最適化の面においても,今回の改良は必要だったに違いない。
さて,恒例のFP32理論性能値を求めてみよう。計算方法はRDNA 3と同じだ。Navi 48ベースのRadeon RX 9070 XTであれば,こうなる。
- 64 CU×4基のSIMD32演算器×32基のFP32演算器×積和算(2 FLOPS)×2970MHz≒48.66 TFLOPS
Navi 44のRadeon RX 9060 XTであれば,こうなる。
- 32 CU×4基のSIMD32演算器×32基のFP32演算器×積和算(2 FLOPS)×3130MHz≒25.64 TFLOPS
推論アクセラレータのFP16演算性能はRDNA 3比で2倍に
GeForce RTXシリーズで「Tensor Core」と呼ばれる推論アクセラレータのRadeon版が,RDNA 3世代で実装されたAI Acceleratorだ。RDNA 4世代では,これの性能強化が図られた。
RDNA 3世代のAI Acceleratorにおける行列演算器(Matrix Core)は,FP16/BF16の演算性能が,FP32の2倍だった。これがRDNA 4になると,FP32の4倍に向上した。RDNA 3比では,演算性能は2倍になる。
 |
また,新たに8bit浮動小数点演算(FP8/BF8)や,8bitおよび4bit整数(Int8/Int4)にも対応。FP16/BF16の2倍ものスループットを実現している。さらに,[a,b,0,0]のような「4:2スパースベクトル要素」については,スループットがさらに2倍速くなるそうだ。
細かいところでは,メモリ上に展開された行列データを読み込むときに,転置行列(transpose Matrix)として読み込ませる機能にも対応した。
 |
ここで,Radeon AI PRO R9700が備えるAI AcceleratorのFP16(Matrix)理論性能値を求めてみよう。
AI Acceleratorは,32bit SIMD積和算器「Wave Matrix Multiply Accumulate」(WMMA)を64基備える。WMMAは,FP16/BF16における2要素の積和算(2 FLOPS)を行えるので,1クロックあたりのスループットは以下のとおりだ。
- 64 WMMA×2要素×2 FLOPS=256 FLOPS/クロック
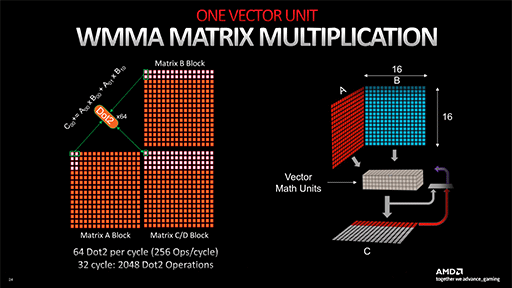 |
CU 1基あたり,AI Acceleratorは2基あり,RDNA 4では,スループットがさらに2倍となるので,1024 FLOPS/クロックとなる。つまりCU 64基,動作クロック2920MHzのRadeon AI PRO R9700のFP16/BF16の理論性能値はこうなる。
- 1024 FLOPS×64 CU×2920MHz≒191.37 TFLOPS
前掲した表にある値と一致するわけだ。
Ray Acceleratorの改善(1)〜BVH8への対応と2倍に向上したレイ探索効率
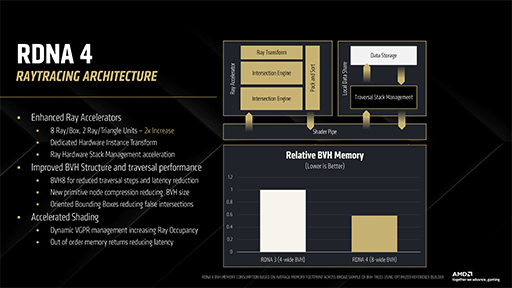
RDNA 4の機能拡張面で,最も力が入っているように思えるのが,レイトレーシングユニットの「Ray Accelerator」だ。RDNA 4のRay Acceleratorは,BVH(Bounding Volume Hierarchy)構造体の「BVH4」と「BVH8」の両方に対応した。また,放たれたレイの探索効率は,RDNA 3に対して2倍に向上したという。
 |
解説の都合上,まずは対応BVH形式の追加から説明していこう。
BVHとは,レイと3Dオブジェクトの衝突判定を高速化するために,レイと3Dオブジェクトの衝突判定に,各3Dオブジェクトをすっぽりと囲う直方体(箱)を用いる構造体のことだ。
関連記事
BVH構造体には何種類かあるが,現在のゲーム向けリアルタイムレイトレーシングで活用例が多いのは,BVH4とBVH8である。
BVH4とは,最上位階層(親ノード)のひとつ下の階層(子ノード)に,直方体が4つある構成のBVH構造体のことだ。一方のBVH8は,子ノードの直方体が8つある。
RDNA 3のRay Acceleratorでは,BVH4に対応していたが,RDNA 4のRay Acceleratorでは,新たにBVH8に対応した。
ちなみに,Microsoftのレイトレーシング向けAPI「DirectX Raytracing」は,BVH4とBVH8の両方に対応しているが,実際のところ,どちらを使うかはGPU任せだ。
子ノードが多いほうが優れるというわけではなく,それぞれに短所と長所がある。BVH4は,1ノードがカバーできる子ノードは4つなので,カバー範囲は狭い。しかし,構造としてはシンプルになるので,メモリ消費量を節約できるメリットがある。
それに対してBVH8は,1ノードでカバーできる子ノードが8つに広がるので,1ノードで広範囲をカバーできる理屈だ。その分,メモリ消費量は大きくなる。
大雑把に言うと,BVH4は,比較的狭いシーンや,細かいジオメトリが密集するような複雑度の高いジオメトリを多く含んだシーンと相性が良い。逆にBVH8は,広大なシーンと相性が良いとされる。
DirectX Raytracingを用いた実際のPCゲームでは,BVH4とBVH8のどちらを使うかは,先述したように,GPUアーキテクチャやGPUドライバが自ら判断して決定する。その判断基準となる情報は,GPUアーキテクチャによって異なるが,BVH構築時にGPUドライバが受け取るジオメトリ情報(インスタンス情報)などがその例だ。
あるいはゲーム側が,フラグを通じて「高速トレース優先」や「高速BVHビルド優先」などを伝えてきた場合は,前者ならばBVH8,後者ならばBVH4を採択するかもしれない。
RDNA 4では,BVH8対応に連動して,Ray Accelerator自体の性能が2倍になった。BVH4より複雑なBVH8に見合う性能を備えた,と言ってもいいだろう。
具体的には,RDNA 4のRay Acceleratorでは,1クロックでBVH8構造体の1ノード,すなわち8個分の直方体を探索できる。ポリゴンとの衝突判定(Intersection)では,1クロックで2つのポリゴンに対しての衝突判定を行えるようになった。
この性能向上によって,従来のBVH4形式に対しては,理論上2倍の速度でBVH4探索とレイ対ポリゴン衝突判定ができるようになる。つまり,BVH4ベースでレイトレーシングを行うゲームは,開発者がとくにRDNA 4最適化を行わなくても,性能向上を期待できることになる。
ここでひとつ,伏線回収的な補足エピソードを。
「PlayStation 5 Pro」の発売後に,ソニー・インタラクティブエンタテインメントは,PS5シリーズのアーキテクトを務めたMark Cerny(マーク・サーニー)氏による「PlayStation 5 Proテクニカルセミナー」を公開した。
その中でCerny氏は,「PS5 ProのGPUは,基本アーキテクチャはRDNA2ベースだが,レイトレーシングユニットについては,(当時からみて)未来のRDNAアーキテクチャのものを先取りして採用した」と述べている。
関連記事



西川善司の3DGE:チーフアーキテクトが語った「PS5 Pro」の秘密とは? レイトレーシングの強化点や超解像機能に注目だ
去る2024年12月19日,SIEは,PlayStationハードウェアのリードアーキテクトであるMark Cerny氏による動画「PS5 Proテクニカルセミナー」を公開した。PS5 Proに盛り込まれた新要素について技術的な説明を行うという非常に興味深い内容であったので,深掘りしてみよう。
RDNA 4アーキテクチャの詳細が明らかになった今では,Cerny氏の言う「未来のRDNA」が,RDNA 4を指していたことは明らかだ。氏が,動画で示していたスライドにあるPS5 Proの性能は,RDNA 4におけるRay Acceleratorの性能と,完全に一致する。
 |
Ray Acceleratorの改善(2)〜BVHにOBB導入
RDNA 4のRay Acceleratorには,地味ながらユニークで優秀な,レイトレーシングのサポート機能が搭載された。それが,BVHにおける自動「OBB」(Oriented Bounding Box)対応機能だ。
BVHの直方体は,「AABB」(Axis-Aligned Bounding Box)で表現することが一般的である。
AABBとは,その直方体におけるすべての辺が,X,Y,Zの各軸に平行となるものだ。多くの場合,3Dオブジェクトをやや大きく囲ってしまうので,冗長性は大きい。しかし,レイとの衝突を,対象となる直方体の8頂点との大小比較だけでシンプルに判定できる特徴を持つ。ようするに,衝突判定時の演算負荷が低いということだ。
これに対してOBBは,3Dオブジェクトをぴったり最小サイズの直方体で囲ったものである。つまり,冗長性は最小限になる理屈だ。しかし,X,Y,Zの各軸とは平行でなくなるため,レイとの衝突判定は,レイをOBBのローカル座標系に変換する幾何変換演算が必要になるので,計算負荷が高くなる。
 |
先述したように,AABBは,3Dオブジェクトを囲っている直方体が,3Dオブジェクトのサイズよりも大きくなりがちだ。そのため,レイとBVHの衝突判定において,3Dオブジェクトには当たりそうもないAABBの外側付近のレイに対しても,衝突したと判定しがちとなる。
一方のOBBは,3Dオブジェクトを囲う直方体が常に最小サイズとなるので,OBBの外側付近に飛んできたレイでも,正しく3Dオブジェクトに衝突する可能性が高くなるわけだ。
レイとBVHとの衝突判定で,3Dオブジェクトに正しくレイが衝突する可能性を高めることは,3Dオブジェクトが密集するシーンにおいて,レイトレーシング性能の善し悪しに直結する。
次のスクリーンショットは,「バイオハザード:RE3」のあるシーンで,レイがBVHと衝突した頻度を表したヒートマップだ。
 |
画像上側の「without OBB」は,AABBベースのBVHで衝突判定を行ったもの。下側の「with OBB」は,OBBベースのBVHで衝突判定を行ったものになる。一目見て,クレーンのようなオブジェクトの周囲で,判定ミスが集中しているのが見てとれよう。
クレーンは長いオブジェクトなので,向きによっては,AABBだと冗長性が大きい箱になってしまう。そのため,本来は通り過ぎるべきレイが,AABBによるクレーンのBVHに衝突してしまっているのだ。
衝突判定をしたところで,どのポリゴンにも衝突しないので,ただBVHをすり抜けて無駄なトラバースを行ったことになる。
一方,OBBベースのBVHでは,レイとBVHとの衝突判定ミスが少ないのが分かるだろう。
下のスクリーンショットは,別シーンのものだが,3Dオブジェクトが密集しているところほど,OBBは無駄なレイトラバースが生じていないことが分かる。
 |
ここまで差が出れば,3Dオブジェクトの多いシーンでのレイトレーシング性能は,相当に変わりそうだ。
ただ,先に述べたように,OBBの活用には,まず3Dオブジェクトを最小サイズで,きっちりと囲める8頂点の算出に演算負荷がかかる。3Dオブジェクトの最大と最小の3D座標だけで算出できる,AABBとは違う。
レイとOBBとの衝突判定も同様で,回転行列の計算が必要になるので,AABBと比べれば演算負荷が大きい。安易にOBBをBVHに使って演算負荷は大丈夫なのか?
AMDは言う。「大丈夫だ。問題ない」。
RDNA 4では,3DオブジェクトをOBB化する専用ハードウェア演算器「OBBエンコーダ」をRay Acceleratorに搭載している。そのおかげで,GPU側の演算器に負荷をかけず,OBB頂点を求められるのだ。つまり,OBB化の処理負荷は,ゼロとみなしてよいのだ。
同様に,レイとOBBとの衝突判定にあたっても,専用ハードウェアのトランスフォーム機構を搭載している。レイは,実質的にOBBのローカル座標系に変換されるので,AABBと同じように,8頂点の大小比較判定で衝突を判定できる。こちらも,AABBとの処理負荷の差は,ほとんどなくなるということだ。
すると気になるのは,RDNA 4におけるOBBベースのBVH構造をどう使うかだ。RDNA 4専用の拡張APIを使わないと利用できないのだとすれば,既存のレイトレーシング対応ゲームで恩恵を受けられないことになる。
このあたりについての回答も,「大丈夫だ。問題ない」と明快だ。
OBB対応は,RDNA 4対応GPUドライバが自動的に行う。既存のレイトレーシング対応ゲームでも,自動的にOBB化されたBVHが活用されるので,性能向上を実現できる。ありがたいことこのうえない。
細かいことだが一応言及しておくと,DirectX Raytracingにおいて,レイと3Dオブジェクトを囲んだ直方体とのBVH構造は,「TLAS」(Top-Level Acceleration Structure)と「BLAS」(Bottom-Level Acceleration Structure)の2階層になっている。RDNA 4の自動OBB対応は,主にBLASに効くことになっているようである。
 |
RDNA 4のメモリ,キャッシュ階層システム
RDNA 4のメモリサブシステムとキャッシュ階層を見ていこう。
まず,L1キャッシュには,目立った変更点はないようだ。WGPの4基ごと(=CU 8基)ごとに1セット256KBという構成は,RDNA 2から変わらない。
Navi 48の場合,CUが64基なので,Navi 48の総L1キャッシュ容量はこうなる。
- 256KB×64÷8=2MB
一方,L2キャッシュは,地味ながら強化されている。
次のブロック図で,中央付近の左右に16基ずつ描かれている「LS」というブロックが,1バンク分のL2キャッシュだ。
 |
ただ,Shader Engineの説明で示したブロック図のように,公式資料でも,この部分を「L2」としている場合もある。
余談だが,LSとは「Local Storage」(LS)の略ではなく,「L$」の表記ミスだ。「$」は,キャッシュを示す記号としてよく使われる。RDNA系GPUでは,CU側にLSと似た名前の「LDS」(Local Data Share,RDNA 4ではShared Memory)がある。これもL$とはまったく別物だ。
さて,RDNA 4のL2キャッシュは,RDNA 3からどう変わったのかというと,容量が少し増えた。
RDNA 4のL2キャッシュは,1バンクあたりの容量が256KBで,この点はRDNA 3と変わらない。変わったのは,L2キャッシュのバンク数だ。
RDNA 3以前,L2キャッシュ数のバンク数は,GDDR6メモリインタフェースのチャネル数に合わせていた。それがRDNA 4では,チャンネル数の2倍に増えているのだ。
たとえばNavi 48の場合,16bit幅のGDDR6メモリを16チャネル接続している。そのため,キャッシュバンク数は2倍の32バンク分となる。
ということで,L2キャッシュの総容量はこうなる。
- 256KB×32バンク=8MB
ブロック図のスライドにある「Optimized Cache System」欄にある内容と一致するわけだ。
ちなみにRDNA 3世代のNavi 31では,L2キャッシュ容量はこうだった。
- 256KB×24バンク=6MB
なお,Navi 44では,L2キャッシュのバンク数はメモリチャンネル数と同じ16となる。よって,L2キャッシュ容量は4MBとなる。
ところで,ブロック図のスライド左の箇条書きに,「2MB aggregate CU Cache」という項目があることに気がついただろうか。これは,項目があるにもかかわらず,ブロック図には描かれていない。
ただ,Navi 48におけるCU 1基あたり32KBのL0キャッシュ総量の2MB(64 CU×32KB)と同じなので,L0キャッシュの表記を変えただけのようだ。
続いては,ブロック図には描かれていないが,RDNA 4のホワイトペーパーにある新しいキャッシュシステム「GL1 Buffer」を見ていこう。
GL1 Bufferは,「Global L1」キャッシュの略と見られ,ようするにL1キャッシュという理解でいいと思う。容量は不明だ。
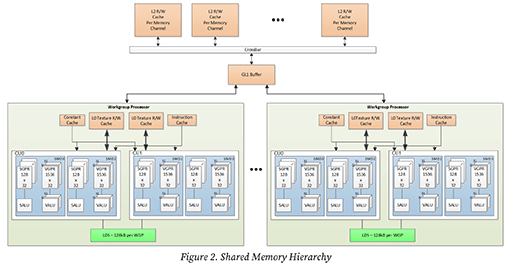 |
このGL1 Bufferの役割について,読み出しと書き出しそれぞれの側面から説明しよう。
まず,L2→GL1→WGP方向,つまりCUからのメモリ読み出しでは,L2キャッシュでヒットした場合,内容が重複しないようにL1キャッシュにデータを移動させる排他キャッシュ制御が働く。
このときのGL1 Bufferは,読み出し専用のL1キャッシュ的に振る舞う。データは,最終的にはWGP内のL0キャッシュに移される。この制御はRDNA 3と同じだ。
一方で,L2←GL1←WGP方向,つまりCUからのメモリ書き出しでは,RDNA 4特有の制御が入る。L1キャッシュは読み出し専用のキャッシュなのだが,メモリの書き出しがリクエストされたときには,GL1 Bufferとして振る舞うのだ。具体的には,メモリの書き出しリクエストをここで集約する処理を行う。
スカラ命令の場合,メモリへの書き出しは,特定のアドレスへの書き出しとなるが,ベクトル演算などでは,SIMD的に複数アドレスへのデータ書き出しリクエスト(Scatter Operation)が発生することがある。
これを,リクエストどおりに書き出すのではなく,時間的な依存関係が崩れないようなアクセス(アトミックアクセス)を担保しつつ,最速でメモリにアクセスできるパターンに整形する制御を行うのだ。
AMDは,GL1 Bufferについて,「いわゆるWrite Combining Cacheのようなもの」と説明している。WGPはレイトレーシングユニット,プログラマブルシェーダ,推論アクセラレータなどを含むが,動作中のアプリケーションによっては,それぞれが局所的なアドレス空間に対してメモリアクセスを頻発させることはあり得る。
この同時多発的に行われるメモリアクセスを少しでも高効率に行わせるための仕組みが,GL1 Bufferと言うわけである。
その効果がどれほどのものかは不明だ。メモリ書き出しが最適化されるので,既存のゲームがRDNA 4への最適化を行わずとも,自動的に性能向上が期待できるだろう。これもありがたい機能だ。
順不同メモリアクセスシステム「Out of order Memory」
GPUの処理系において,高性能を発揮するための要件とは,演算速度が速いだけでなく,メモリアクセスをどれくらい隠蔽できるかにかかっていると言われている。
GPUにおけるメモリアクセス時間の隠蔽は,時間のかかるメモリアクセスが完了するまでの待ち時間の間,演算処理対象を別のデータスレッド(※AMD製GPUではWave,NVIDIA製GPUではWarp)に一時的に切り換えることで実現するのが一般的だ。
切り換えた別のデータスレッドでメモリアクセスが発生したとしても,その処理対象データがキャッシュメモリにあれば,そのデータスレッドの処理を先に実行できる。つまり,先に動いていたメモリアクセスの待ち時間を有効活用したことになるわけで,これがメモリアクセス時間の隠蔽だ。
実際には,切り換えた別のデータスレッドにおいても,メモリアクセスとキャッシュミスが発生する場合もあり,その場合は,GPUコアの汎用ベクタレジスタ(VGPR,後述)が尽きるまで,処理対象データスレッドの切り替えを繰り返すことになる。
RDNA 4で搭載された「Out of Order Memory」(順不同なメモリアクセス,以下,OOOM)は,メモリアクセス時間の隠蔽の進化版といえる技術だ。
RDNA 3までも,ハードウェアキュー側にメモリアクセス要求を集めて,メモリアクセスを最適化する仕組みは搭載されている。しかし,無数のメモリアクセス要求を,それぞれの発生時間を入れ替えて調整する制御までは行っていなかった。
というのも,たとえば同一アドレスに対して,「読んでから書く」処理と「書いてから読む」処理を不用意に入れ替えると,依存関係を壊して正常なプログラム実行ができなくなるからだ。
そこで,RDNA 4では,2つの手法でメモリアクセス要求の最適化を行う。その機能名がOOOMだ。OOOMは,APIから活用するものではなく,既存のゲームに対しても,プログラムの改変不要で自動的に性能向上する機能である。
ひとつめの最適化方法は,RDNA 3以前に存在したバグの修正のようなものだ。
RDNA 3以前のGPUでは,異なる2つのデータスレッドからメモリアクセスが生じたときに,1つはキャッシュにあり,もう1つはキャッシュになかった場合に,キャッシュにあった側がキャッシュ内のデータをすぐに利用できない問題があった。これにより,キャッシュへのアクセス性能を損ねていたのだ。
この問題は,キャッシュミスした側のメモリアクセスが,キャッシュヒットした側より早くに発生した場合に起きると分析されている。次のスライドは,その状態を示したものだ。
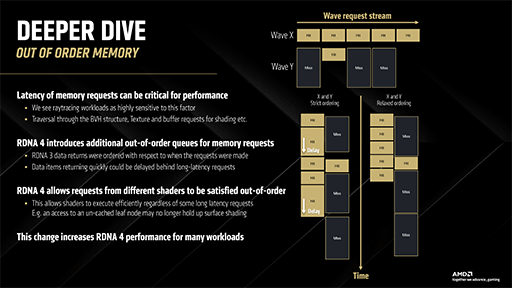 |
いうまでもないが,RDNA 3以前においても,キャッシュシステム側で時間方向のメモリアクセスが矛盾しないように制御していた。しかし,当時のAMDは,動作の安定を最優先に考えて,キャッシュヒットしても,時間方向で逆転したメモリアクセスの順序入れ替えはしなかったという。
AMDのスタンスとしては,「動作としては正常だったのでこれはバグではない。制御が過保護だっただけ」のようだ。いずれにせよRDNA 4では,この過保護が修正されたということだ。
2つめは,メモリアクセス種別の細分化だ。
一言でメモリアクセスといっても,それぞれに目的がある。種類の異なるメモリアクセスは,完全な独立事象といえるので,時間軸方向の最適化(≒順不同実行)をしやすい。
たとえば,テクスチャマップへのアクセスと,レイトレーシングにおけるBVH探索は,どちらもグラフィックスメモリからの読み出しだ。仮に,これらのアクセス先が,物理アドレス空間上で隣接していたとしても,依存関係はあり得ない。それなら順不同でアクセスしてもいいだろう。
AMDによると,RDNA 4では,メモリアクセスを7種類に分類している。
- 汎用ロード(読み出し)
- 汎用ストア(書き出し)
- テクスチャマップアクセス
- レイトレーシングにおけるBVH交叉判定
- 座標値,カラー値,マルチレンダーターゲット(MRT)など
- GPGPU(Compute Shader),Mesh Shaderなど
- スカラ演算の出力値
通常のラスタライズ描画とレイトレーシング描画を並行して行う現代のゲームグラフィックスにおいて,OOOMは,性能向上に大きく貢献しそうである。なにしろ,RDNA 4世代GPUでゲームを実行するだけで,性能が向上するのだ。
動的割り当てに対応したVGPR
GPUでは,データスレッドを処理していく過程で,汎用ベクタレジスタ(Vector General Purpose Register,VGPR)を消費する。
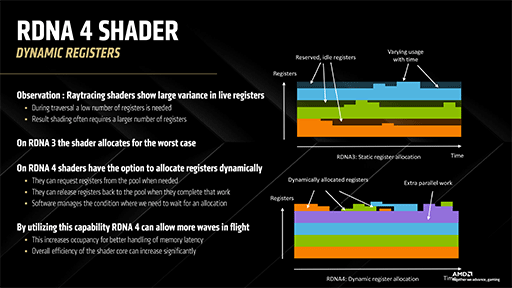
VGPRは,GPU内で有限なリソースだ。シェーダスレッドが起動されると,その時点でシェーダが使用可能なVGPRから,適切な量が割り当てられる。VGPRの総数が多ければ,メモリアクセス時間の隠蔽時に行われるデータスレッドの切り替え回数を増やせる理屈だ。
RDNA 3以前では,シェーダスレッドが立ち上がるたびに,その時点で仕様可能な最大数のVGPRを割り当てていた。
レイトレーシング関連は,短時間で処理が終わるものの,膨大な数のシェーダスレッドを同時起動する。そのため,RDNA 3以前のVGPR割り当てアルゴリズムだと,VGPRが早く枯渇しやすくなってしまったのだ。VGPRが枯渇すると,どこかのシェーダスレッドがVGPRをリサイクル(解放)してくれるまで,次のスレッドが待ち続けることになってしまう。
そこでRDNA 4では,VGPR割り当て方法を刷新。シェーダスレッドが起動したときには,まず必要最低限のVGPRだけを割り当てる。その後,データスレッドの切り替えなどが発生して,より多くのVGPRが必要になったときに,必要な数だけ割当量を増やす仕組みに変わったのだ。
シェーダスレッドが完全に終了したら,そのスレッドが確保していたVGPRも解放して,再利用可能なVGPRとしてリサイクルする。
AMDは,この動的VGPR割り当ての仕組みを,「Dynamic Register」と命名した(※ホワイトペーパー上では「Dynamic VGPR」となっている)。
 |
この改善により,有限な資源であるVGPRを,必要なスレッドに必要なだけ割り当てられる傾向が強まり,性能向上が期待できるようになるわけだ。
Dynamic Register機能は,RDNA 4対応GPUドライバ側が自動的に活用するので,既存のゲームにおいてもプログラムの改変は不要で,そのまま機能する。これまた,ありがたいことだ。
ただし,Dynamic Registerは,今のところ「WAVE32」のサイズに限定されている。また,シェーダスレッドの種別も,Compute Shader限定だ。頂点シェーダやピクセルシェーダなどには,Dynamic Registerを使えない。
「レイトレーシングでは使えないの?」と思った人もいると思うが,問題はないそうだ。
DirectX Raytracingのレイトレーシングパイプラインは,グラフィックス系のシェーダスレッドではなく,Compute Shader系スレッドとして起動されるので,Dynamic Registerは有効である。しかし,同じレイトレーシングでも,ピクセルシェーダスレッド中に記述したインラインレイトレーシングの場合は,適用外となる。
Dynamic Register機能の制限について,AMDは,「今のところは」と説明しているので,将来のRDNAでは,制限が撤廃される可能性は高い。
RDNA 4はゲーム側の改変なしで効く新機能が多い
RDNA 4では,そのほかにも,内蔵ビデオプロセッサ「Video Core Next」(VCN)に,以下のような強化も行われている。
- H.264低遅延エンコードモードの画質が25%向上
- H.265エンコードが11%画質向上
- AV1エンコードにおいてBフレーム参照が高効率化
- 720p解像度のエンコード処理が30%高速化
1と4は,リモートプレイなどで効果を発揮する。3は,双方向に過去フレームを参照したエンコードにおいて,画質の向上に役立つ。2とともに,ビデオ編集時に効力を発揮しそうだ。
 |
今回も長々と,新GPUアーキテクチャの特徴を解説してきたわけだが,最後に筆者の所感を述べて締めたい。
技術的な視点から見ると,RDNA 4アーキテクチャは,興味深い工夫が目白押しのGPUであった。なにより,新機能や改良ポイントのほぼすべてが,既存のゲームのプログラムを改変することなく,いかに速く動かせるかにフォーカスして開発されている点は,潔いというか好感が持てる。AMDらしいというべきか。
NVIDIAのGeForce RTX 50シリーズは,無段階LOD対応のレイトレーシングシステム「Mega Geometry」や,AI支援による新レンダリング技術「ニューラルレンダリング」など,次世代技術を山盛りに搭載している。だが,そのほぼすべては,ゲーム側で新たに対応しないと利用できない。
新しい技術の分野を意欲的に切り拓いていく姿勢は,さすがNVIDIAといったところだが,既存や最新のゲームで,それらの機能が生かされる可能性は低いだろう。
本稿執筆時点における,RDNA 4世代GPUの最上位モデルは,Radeon RX 9070シリーズで,GeForce RTX 5070シリーズを仮想敵に想定したものだ。つまりAMDは,最上位クラスのGeForce RTX 5080シリーズ以上とは,あえて勝負を避けた製品戦略で臨んだことになる。
この戦略から,AMDの弱気な姿勢が見て取れるのは,少し残念だ。一方で,Radeon RX 9070シリーズは,新機能のほぼすべてが,既存や最新のゲームで利用できるところに大きな魅力がある。
GeForce RTX 5070クラスは,人気の市場なので,ここにAMDがライバル製品を,一点集中でぶつけてきたことの意義は大きい。AMDは,Radeon RX 9070シリーズの実勢価格を,仮想敵であるGeForce RTX 5070シリーズよりもやや安価に設定しているので,価格競争力はある。
とはいえ,NVIDIAのGeForce RTXシリーズは,価格差を覆すほど人気があるのが恐ろしいわけだが。今後,「Radeon RX 9080」のような上位モデルが出てれば,もう少し,GPU市場をかき回しそうな気がする。
AMDのRadeon RXグラフィックスカード情報ページ
- 関連タイトル:Radeon RX 9000
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー